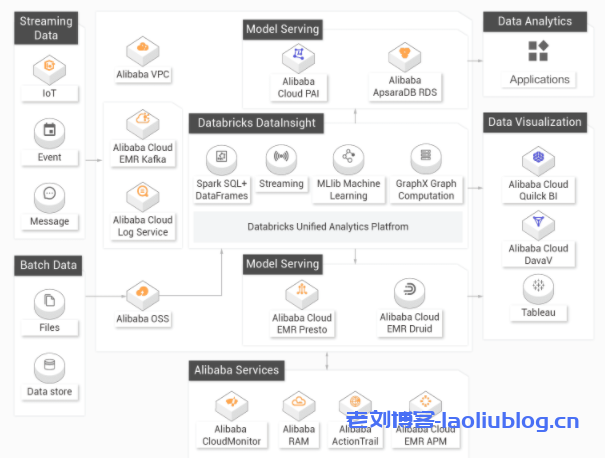
阿里云Databricks数据洞察是基于Apache Spark的全托管数据分析平台,内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可同时满足数据分析师、数据开发工程师和数据科学家的分析需求,实现协同合作和数据共享。满足用户在大数据下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等场景需求。
产品优势
极致性能
Databricks Runtime内核,性能明显优于社区版Spark,最高可达50倍提升。满足高性能、高稳定性、可弹性的计算需求。
批流一体
Databricks Delta Lake为数据湖分析提供了ACID事务能力,轻松处理包含数十亿文件的PB级表的元数据信息,实现了批流一体的数据处理方式。
协同分析
同时满足数据科学家、数据工程师以及业务分析师的计算需求,提供交互式的协同分析工作平台。
数据共享
计算存储分离,减少数据冗余,实现多引擎间的数据共享,降低数据存储成本,内置对OSS的访问性能优化。
精心打造的功能
全托管分析平台,快速拉起Spark全托管的集群,操作简单,按需付费。
集群规模 用户根据需求设置节点数量,支持集群高可用。
机型选择 支持ECS通用型、计算型和内存型三种实例规格族。
弹性能力 集群规模可动态扩展,调整计算资源大小,达到成本最优。
交互式协同工作,多种用户角色共享数据,交互式协同合作。
Notebook 可以协同工作的工作空间,交互式的作业执行方式,支持Spark、PySpark、Spark R和Spark SQL类型的作业,分析结果可视化展示。
统一元数据 集群之间共享数据库、表的元信息,无需重复创建。
完全兼容Spark生态,100%兼容开源Spark,迁移成本低,性能表现优异。
Databricks Runtime,在Apache Spark基础上做了大量的性能优化,且针对阿里云OSS做了I/O优化,提供了更快速、更高效的计算引擎。
Databricks Delta Lake,较开源Delta Lake,功能更完备,对核心功能点均有更深度的优化和性能提升。
企业安全性,与阿里云RAM集成,可以根据用户和角色做权限控制,保障数据安全性。
产品架构和典型场景
典型场景:数据获取,接收实时产生的流式数据和外部云存储上批量数据。数据ETL,持续高效地处理增量数据,支持数据的回滚和删改,提供ACID事务性保障。BI数据分析,支持Ad hoc查询,无缝对接多种BI分析工具。AI数据探索,支持机器学习。